


How to Make a robots.txt File for SEO Success
Crafting Your Own Robots.txt: A Step-by-Step Guide
If you publish anything on the web, you’re already in a conversation with crawlers. Some of them are helpful, like Googlebot and Bingbot. Others are noisy or just not relevant to your goals. A small text file at your domain’s root gives you a polite way to set expectations: robots.txt.
That tiny file can save server resources, keep search engines focused on high‑value content, and reduce noise in your analytics. The good news is you can make one in minutes with a plain text editor.
Let’s get practical and build a solid file you’ll feel confident deploying.
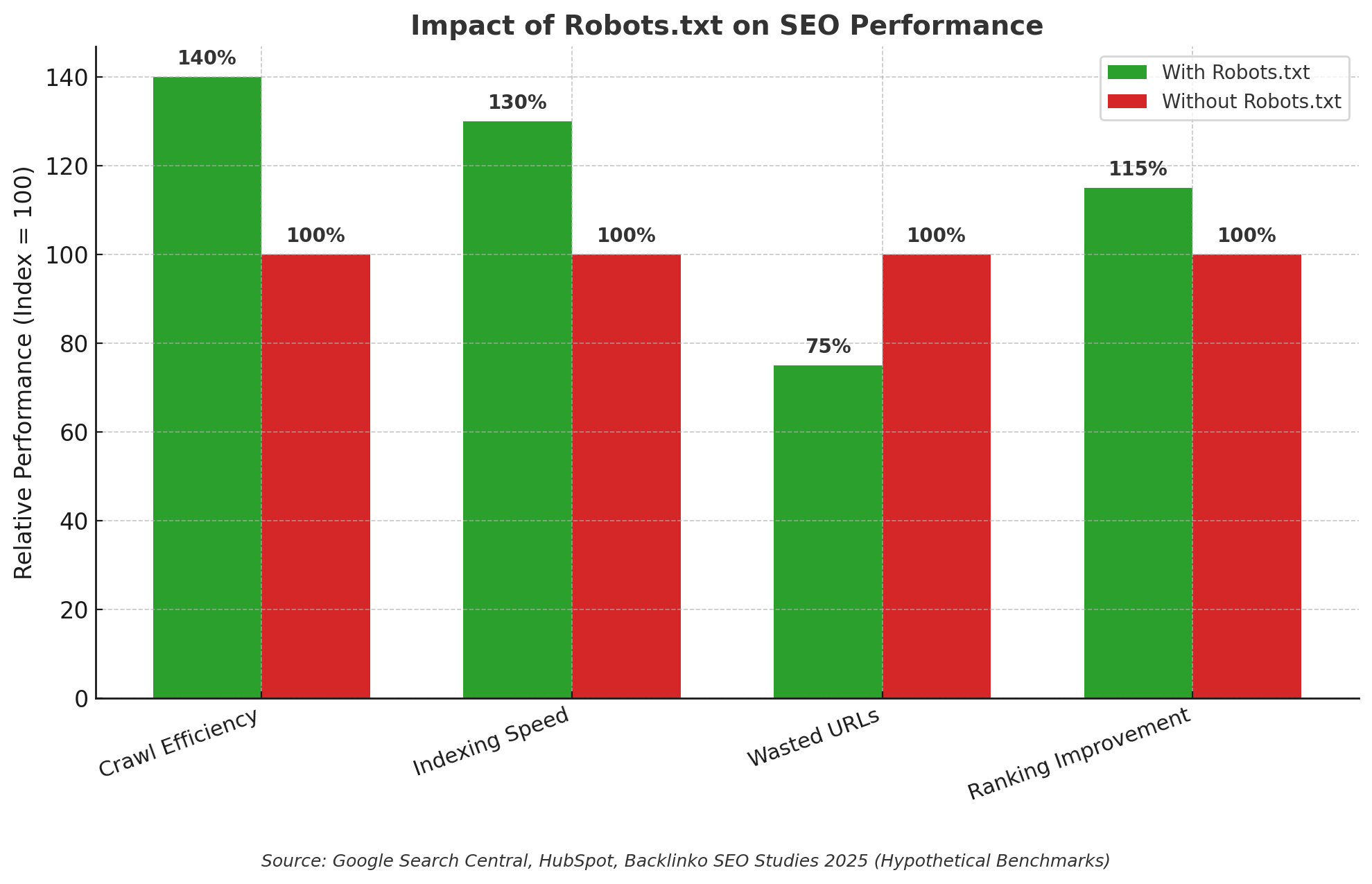
What robots.txt actually controls
Robots.txt implements the Robots Exclusion Protocol. Polite crawlers fetch this file first, then decide where they’re allowed to crawl. The file does not enforce security. It signals intent. Good bots follow it. Bad bots might ignore it.
Key ideas to keep in mind:
- It controls crawling, not indexing. A disallowed URL can still appear in search if other sites link to it. Search engines might list the URL without a snippet because they never crawled the content.
- It’s public. Anyone can view https://yoursite.com/robots.txt, so do not list sensitive paths you would rather keep private.
- It’s a request, not a rulebook. For anything truly private, use authentication or restrict access at the server or application level.
When does a robots.txt file help?
- You want to reduce crawl load from low‑value areas like internal search, filters, cart, login, or paginated duplicates
- You’re wrangling faceted navigation and parameter chaos on a large ecommerce site
- You run documentation or blog archives and want bots to focus on fresh, canonical pages
- You want to communicate your sitemap location to help discovery
Crawling vs indexing: which tool to use and when
Use robots.txt for crawl control. Use meta robots tags or X‑Robots‑Tag for index control. They’re complementary.
| Aspect | robots.txt | Meta robots tag | X‑Robots‑Tag (HTTP header) |
|---|---|---|---|
| Where it lives | /robots.txt at the site root | In the of an HTML page | In the HTTP response headers |
| What it controls | Crawling access to paths | Indexing and link following on that page | Indexing and link following for any resource type |
| When it applies | Before a bot fetches a URL | After the bot fetches the page | When the URL is fetched |
| Scope | Global or directory patterns | Page level | Per URL, and easy to apply to whole file types |
| Good for | Blocking low‑value sections from crawl | Keeping individual pages out of search results | No‑indexing PDFs, images, or other non‑HTML files |
| Limitation | Advisory only; blocked pages might still appear by URL | Bot must crawl the page to see the tag | Bot must fetch the resource to see the header |
Two practical rules:
- If you need a page kept out of search results, use noindex. That page must be crawlable for the tag or header to be seen, so do not disallow it in robots.txt.
- If you want to reduce crawl on an entire section that offers little search value, disallow it in robots.txt.
Before you write the file
Start with a quick inventory.
- List content that must remain crawlable: key pages, CSS, JavaScript, images used in templates, APIs that render content, sitemap files
- List content that wastes crawl capacity or clutters reports: cart, login, checkout, thank‑you pages, internal search, filtered URLs, staging endpoints
Avoid blocking required resources. Google needs CSS and JS to render and evaluate your pages. If crawlers can’t fetch them, mobile and structured data assessments can go sideways. When in doubt, test with the URL Inspection tool in Search Console after you deploy your file.
Step‑by‑step: create a robots.txt that works
1. Decide what to allow and what to block
A simple starting set for many sites:
- Allow everything by default
- Disallow low‑value paths: /cart/, /checkout/, /login/, /search/, /thank‑you/
- Keep assets open: /css/, /js/, /assets/, /api/
2. Target all crawlers or specific ones
You can write a group that applies to all bots, or tailor a group to a named user‑agent. For example, you might restrict a less important crawler more aggressively than Googlebot or Bingbot.
3. Write the directives in plain text
Use a basic editor like Notepad on Windows or TextEdit in plain text mode on Mac. Save the file as robots.txt. Do not use a word processor.
Structure:
- Start a group with User-agent
- Add Disallow and Allow rules for that group
- Use blank lines to separate groups
- Add your sitemap URL at the end
Example:
Tips that prevent common mistakes:
- A blank Disallow line means everything is allowed for that group
- Specific rules win over broader ones
- Comments begin with # and are ignored by crawlers, which makes them perfect for documenting intent
4. Upload the file to your root directory
Place robots.txt at the top level of the domain. The final URL must be exactly https://www.example.co.nz/robots.txt. Use your hosting file manager, an FTP client, or your CMS.
WordPress users can manage robots.txt with Yoast SEO, Rank Math, or by placing a physical file on the server. If you use a plugin interface, ensure it writes to the actual root.
5. Validate and test immediately
- Visit https://www.example.co.nz/robots.txt in a browser and confirm it loads
- In Google Search Console, open the robots.txt report to check fetch status and parse errors
- Use a site audit tool to simulate crawling with your rules and spot accidental blocks
- Test important URLs in the URL Inspection tool to confirm “Allowed” and proper rendering
Wildcard patterns that give you precision
Wildcards help match sets of URLs without enumerating each one. Use them carefully.
- Asterisk * matches any sequence of characters
- Dollar sign $ anchors a rule to the end of a URL
Good patterns:
- Disallow: /search* to block /search, /search?q=shoes, and /search/results/2
- Disallow: /thank-you$ to block only /thank-you, not /thank-you/page
- Disallow: /category/*?sort= to block sorting parameters
Risky patterns to avoid unless you’re sure:
- Disallow: /*.php which blocks every URL ending in .php, including product.php or index.php
- Disallow: /*.html$ which might remove your entire site from crawl if your pages end with .html
When patterns get tricky, test them in a crawler and with sample URLs before shipping to production.
Avoid blocking essential resources
Crawlers need to render your layout and scripts to evaluate mobile friendliness and structured features. Keep these folders open unless you have a strong reason to restrict them.
Keep crawlable:
- /css/
- /js/
- /assets/
- /images/
- /api/ if your templates request it
After you deploy, run a fetch and render on a few key pages. If you see “Blocked by robots.txt” for a dependent resource, revisit your rules.
Targeting or blocking AI crawlers
Many AI models gather training data by crawling public sites. You can signal permission or refusal in robots.txt with named user‑agents.
To block OpenAI’s GPTBot:
To block a set of well known AI crawlers:
Important context:
- Compliance is voluntary. Reputable operators tend to respect robots.txt. Others may not.
- If protection is essential, combine robots rules with technical controls: authentication, rate limiting, WAF rules, or bot management.
- A proposed llms.txt file may appear over time in more places, though adoption is still low. Keep an eye on developments, but treat robots.txt as your primary public signal for now.
If your strategy favours brand reach, you might allow AI crawlers. If you care more about control and licensing, consider disallowing named agents and backing that up with server‑side defences and clear terms of use.
Practical examples for common sites
Blog or content site
For a typical blog or content-focused website, you want search engines to crawl and index your articles, category pages, and images, but avoid low-value pages like internal search results or admin areas.
Example robots.txt:
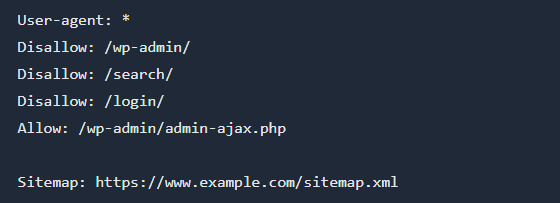
Explanation:
- and are blocked to keep admin and login pages private.
- is blocked to prevent indexing of internal search result pages.
- AJAX handler is allowed for site functionality.
- Sitemap is provided for better discovery.
Ecommerce site with filters
Ecommerce sites often have many URLs generated by filters, sorting, and pagination. You want to keep product and category pages crawlable, but block parameter-based duplicates and sensitive paths.
Example robots.txt:
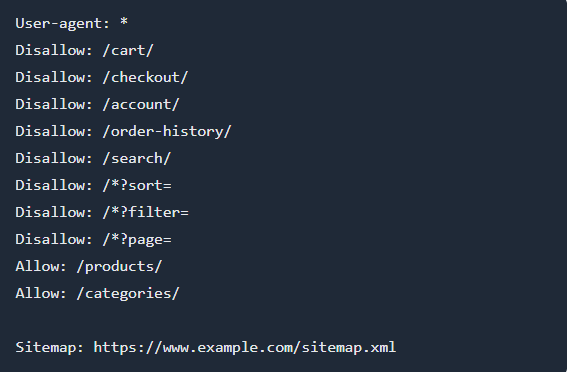
Explanation:
- Blocks cart, checkout, account, and order history pages.
- Blocks URLs with sort, filter, and page parameters to avoid duplicate content.
- Allows main product and category directories.
- Sitemap is included for efficient crawling.
SaaS app with a marketing site
For SaaS companies, you want your marketing pages indexed but keep the app, dashboard, and user-specific areas private.
Example robots.txt:
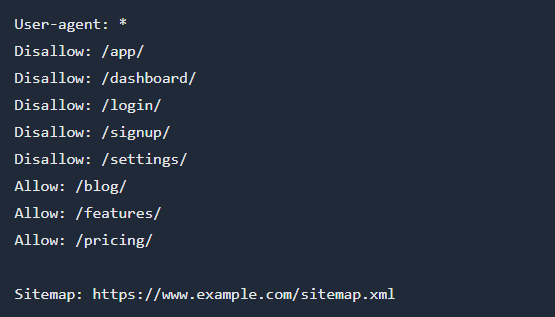
Explanation:
- Blocks all application and user-specific paths.
- Allows marketing pages, blog, features, and pricing.
- Sitemap helps search engines find important public pages.
Note: Avoid listing private dashboard paths that reveal more than you intend. Use authentication to protect the app rather than relying on robots.txt.
Testing, monitoring, and staying on top of changes
Testing does not end at upload. Make checks part of your routine.
In Google Search Console:
- Robots.txt report: verify it was fetched without errors
- URL Inspection: confirm important pages are allowed and rendered
- Page indexing report: review “Blocked by robots.txt” and confirm it matches your policy
- Crawl stats: look for a healthy share of requests hitting your important sections
In your crawler or site audit tool:
- Crawl obeying robots.txt and review what gets skipped
- Validate wildcard logic on example URLs
- Flag blocked CSS or JS files
From your server or CDN logs:
- Filter by user‑agent strings like Googlebot, Bingbot, GPTBot
- Check whether disallowed paths are being hit
- Confirm that new content receives crawler attention shortly after publishing
Revisit robots.txt any time you restructure URLs, add sections, roll out a new theme, or migrate hosting. A short review now prevents weeks of silent crawl issues.
Common mistakes and quick fixes
- Blocking CSS or JS: remove those disallows and test rendering again
- Disallowing a page that also carries a noindex tag: pick one intent; if you want it out of search, remove the disallow so crawlers can see the noindex
- Using a word processor: create robots.txt in plain text to avoid stray characters
- Placing the file in a subfolder: move it to the domain root so crawlers can find it
- Over‑broad wildcards: tighten the pattern, then retest with sample URLs
- Forgetting sitemaps: add a Sitemap line and submit the sitemap in Search Console
- Copying rules between domains without review: audit the new site structure first
A few advanced notes that pay off
- Specificity wins. If two rules match, the more specific path usually applies. Use Allow to carve out exceptions from a Disallow.
- Empty Disallow means “allow all” for that group. Some admins use it to explicitly state an allow‑all stance for a bot.
- Non‑standard directives exist. Crawl‑delay is supported by some bots, ignored by others. Googlebot ignores it, so rely on server‑side rate controls for Google if needed.
- Remember subdomains. Each subdomain needs its own robots.txt if you want distinct policies.
- Canonicals and robots.txt work well together. Let canonical tags point to preferred URLs while robots.txt trims crawl waste for infinite combinations you cannot consolidate.
Quick reference: directives you’ll actually use
- User-agent: names the crawler. Use * for all
- Disallow: blocks crawl of matching paths
- Allow: re‑permits a subpath otherwise caught by Disallow
- Sitemap: absolute URL to your sitemap file
A simple decision tree for everyday cases
- Want a section not crawled because it’s low value or duplicative? Use robots.txt Disallow.
- Want a page invisible in search results? Leave it crawlable and add a meta robots noindex, or set X‑Robots‑Tag via headers for non‑HTML files.
- Want to keep content private? Require authentication or block at the server. Do not rely on robots.txt.
- Want to reduce server load from a chatty bot? Create a stricter user‑agent group or use a WAF to throttle.
- Want to avoid AI training usage? Disallow known AI agents, then support with technical and legal measures.
A compact checklist you can reuse
- Map your site: note must‑crawl resources and low‑value areas
- Draft robots.txt in plain text with User‑agent groups, Allow, Disallow, and Sitemap
- Keep CSS, JS, images, and required APIs open
- Add patterns carefully. Test any wildcard rules with sample URLs
- Upload to the root so it resolves at /robots.txt
- Validate in Search Console and with a site audit crawler
- Inspect server or CDN logs for real bot behaviour
- Submit or update your sitemap in Search Console
- Recheck after deployments, theme changes, or URL restructures
- Update rules for new crawlers, including AI agents, as needed
With a tidy robots.txt guiding crawlers and a habit of testing changes, you’ll concentrate search engines on the content that matters and keep your site running fast for real visitors.