



什么是robots.txt文件:基本介绍与其意义
什么是robots.txt文件:基本介绍与其意义
很多网站上线后,页面明明存在,却迟迟没有被搜索引擎正常抓取;还有一些站点,服务器压力并不高,却总被无意义的参数页、筛选页和测试目录消耗抓取资源。这个时候,很多人会想到一个老朋友:。
它看起来只是一份很短的纯文本文件,实际却是网站抓取管理里的基础设施。用对了,它能帮助搜索引擎更高效地访问真正重要的内容;用错了,也可能把核心页面拦在门外,影响收录与流量表现。
robots.txt 文件的定义与核心作用
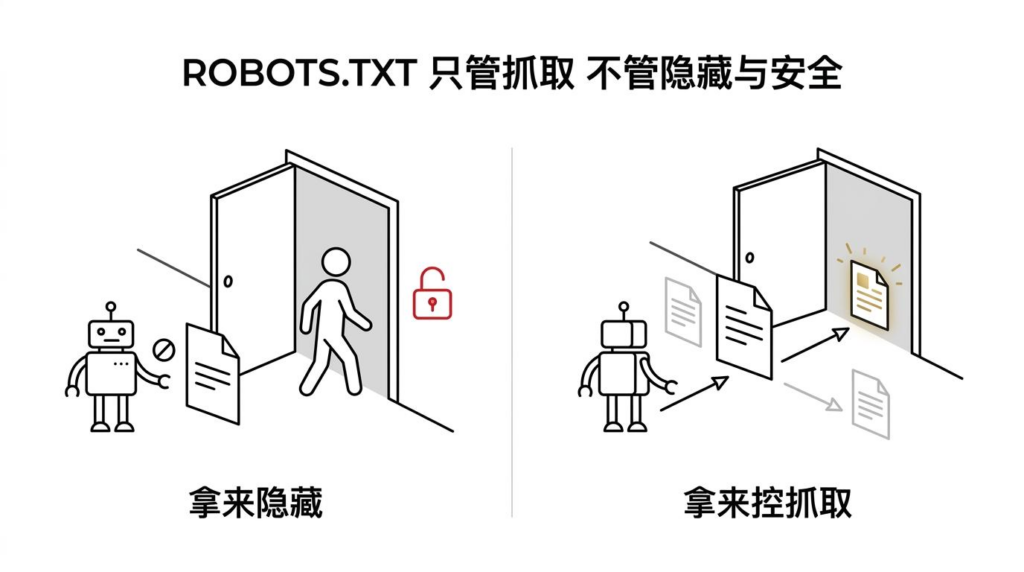
是一种面向爬虫的访问规则文件,主要作用是告诉搜索引擎或其他自动抓取程序,站点中的哪些路径可以抓,哪些路径不建议抓。它属于“抓取控制”,不是“内容保护”。
这点非常关键。很多人把 当作隐藏页面的方式,实际上它并不能保证页面不被别人看到,也不能阻止用户直接访问 URL。更现实的情况是,即使某个页面被 屏蔽,只要外部还有链接指向它,搜索引擎仍可能记录这个 URL,并在搜索结果中展示,只是没有抓取到页面正文内容而已。
对比图展示 robots.txt 适合用于抓取控制,不适合用于隐藏页面或做安全防护。
从 SEO 角度看, 最直接的价值有两个:一是减少低价值页面对抓取资源的占用,二是让重要页面获得更稳定的抓取机会。对内容量大、参数复杂、栏目众多的网站,这一点尤其明显。
在使用上,可以先记住一个简单判断:
- 适合: 控制爬虫访问站内特定路径
- 适合: 限制筛选页、搜索结果页、测试目录被反复抓取
- 不适合: 隐藏敏感信息或后台地址
- 不适合: 代替登录验证、权限控制或真正的安全措施
robots.txt 文件放置位置与作用范围
官方规范与主流搜索引擎文档都强调, 必须放在站点的顶层目录,也就是根路径下。标准形式是:
放在子目录里通常无效,像 这种位置,搜索引擎不会把它当成整站规则文件。文件本身应为 UTF-8 编码 的纯文本,而且一个主机范围内只识别这一份。
另一个经常被忽略的问题,是它的“作用边界”非常严格。规则只对当前协议、主机和端口生效,不会自动扩展到别的子域名、别的协议,或别的端口。也就是说, 的规则,不会自动管到 ,也不会管到 。
下面这个表格很适合快速判断:
| robots.txt 位置 | 是否对全站生效 | 说明 |
|---|---|---|
| 网站根目录(/robots.txt) | 是 | 标准位置 |
| 子目录(/abc/robots.txt) | 否 | 子目录中的文件不作为整站规则 |
| 仅 HTTP(http://) | 否 | 不自动作用于 HTTPS |
| 子域名(sub.example.com) | 否 | 子域名需要单独配置 |
| 不同端口(:808等) | 否 | 不同端口视为不同作用范围 |
如果网站同时存在 与非 、HTTP 与 HTTPS、多语言子域名或独立业务子域名,就需要分别检查每个入口是否都部署了正确的 。
robots.txt 语法规则与常用指令
的语法并不复杂,常见指令主要有 、、 和 。其中,前 3 个直接参与抓取规则, 则用于告诉搜索引擎站点地图的位置。
| 指令 | 作用 | 常见用途 |
|---|---|---|
| User-agent | 指定规则面向哪个爬虫 | 代表通配的大多数爬虫 |
| Disallow | 不允许抓取某个路径 | 屏蔽后台、测试目录、参数页 |
| Allow | 明确允许抓取某个路径 | 在大范围屏蔽下放行特定文件夹或文件 |
| Sitemap | 声明站点地图地址 | 帮助搜索引擎发现重要 URL |
一个常见示例如下:
这段规则的意思是:大多数爬虫不要抓取 和 下的内容,但 这个子路径可以抓。同时,站点地图位于指定地址。
如果你的网站有多个爬虫策略,也可以按组编写规则:
这里的含义是, 不抓 ,其他通用爬虫不抓 。写规则时要格外谨慎,少一个斜杠、多一个目录名,都可能改变抓取范围。
robots.txt 创建步骤与配置方法
创建 的流程并不复杂,难点主要在“规则设计”而不是“文件生成”。一个更稳妥的做法,是先列出网站里哪些目录属于低价值抓取对象,再判断这些路径是否真的应该被拦截。
通常可以按这个顺序处理:
- 盘点全站 URL 类型
- 识别低价值页面
- 编写最小必要规则
- 上传到根目录
- 测试是否误伤重要页面
- 上线后持续观察抓取与收录变化
如果站点体量不大,规则往往很简洁。真正需要精细配置的,多半是电商、资讯平台、工具站、论坛这类 URL 结构多、参数组合多的站点。规则写得越多,误封的风险也会越高,所以“够用就好”往往比“写满所有可能情况”更有效。
一个比较实用的初始模板可以写成这样:
这类配置适合先控制明显不需要进入搜索结果的功能页,再逐步细化。
robots.txt 与 SEO 优化的真实关系
很多人一提到 SEO,就把 robots.txt 视为“收录开关”。这种看法其实并不准确。robots.txt 影响的是抓取,而不是直接决定是否索引。虽然抓取与索引相关,但两者并不等同。
在 SEO 实践中,robots.txt 的最大价值在于优化抓取资源,减少无效抓取。根据 Google 的公开数据,大型网站每天会被搜索引擎抓取数十万甚至上百万次。如果没有合理的抓取规则,像站内搜索结果页、重复筛选页、会话参数页、临时测试目录等低价值页面,可能会占用大量抓取配额,导致真正重要的内容抓取频率下降。数据显示,电商类网站中,超过30%的抓取请求可能落在这些“无价值”页面上,影响整体收录效率。
实际优化时,建议定期分析服务器日志,识别被频繁抓取但无助于 SEO 的路径。例如,某大型电商平台通过 robots.txt 屏蔽了参数组合页和测试目录后,主内容页面的抓取频率提升了20%,新页面的收录速度也更快。对于新闻、内容型网站,合理配置 robots.txt 能有效避免重复内容被过度抓取,提升核心内容的曝光机会。
需要特别注意的是,如果一个页面已经被 robots.txt 屏蔽,搜索引擎通常无法抓取其内容,也无法读取页面中的 noindex 指令。这意味着,单靠 robots.txt 并不能彻底阻止页面被收录。要让某个 URL 真正不出现在搜索结果中,往往还需要结合登录限制、权限控制、正确的 HTTP 状态码,或者允许抓取后再用 noindex 控制索引。
因此,专业 SEO 圈通常将 robots.txt 视为“抓取层”的工具,而不是“收录层”或“安全层”的解决方案。正确理解和配置 robots.txt,不仅能提升网站整体抓取效率,还能为核心内容争取更多曝光机会。
robots.txt 抓取缓存、大小限制与异常状态处理
这部分很少被讨论,却直接关系到规则是否能及时生效。
搜索引擎不会在每次访问页面前都重新下载一次 。主流搜索引擎通常会缓存它,缓存时间常见在约 24 小时左右。也就是说,你今天改了规则,效果不一定会立刻体现。对上线窗口紧、活动页多的站点,这个延迟必须预先考虑进去。
文件大小也不是无限制的。公开文档里提到,解析上限常见为 500 KiB。超出这个体积后,后面的内容可能被忽略。站点越大,越应该避免把 写成庞杂的规则仓库。
还有两个细节值得注意。第一,规范层面对重定向有要求,爬虫在请求 时应至少跟随多次连续重定向,常见标准是 5 次。第二,文件不可访问时,不同爬虫的处理并不完全一样,临时错误、网络故障、异常响应,都可能带来你预期之外的结果。
与其赌搜索引擎“会怎么理解错误”,不如把基础设施做稳定:
- 服务器可用性: 保证根目录文件可稳定返回
- 响应状态: 避免异常重定向、循环跳转和错误码波动
- 文件体积: 保持简洁,别把规则堆到上限附近
- 发布时间: 重要改动预留缓存生效时间
robots.txt 常见误区与排查重点
最典型的误区,是把 robots.txt 当成“禁止别人看到内容”的工具。实际上,robots.txt 文件本身就是公开可访问的,任何人都可以直接访问并查看其中列出的路径,这反而可能让敏感目录暴露在外。据统计,超过60%的数据泄露事件与配置不当有关,其中不少案例就是因为敏感路径被 robots.txt 公开,导致被恶意爬虫或攻击者利用。因此,如果某些内容确实不应被外部访问,首选措施应是认证、授权和服务端拦截,而不是仅依赖 robots.txt。
另一个常见误区,是把所有不希望被收录的页面都写进 robots.txt。表面上看似简单省事,但实际上会影响搜索引擎对页面的进一步判断。Google 官方曾指出,robots.txt 屏蔽的页面无法被抓取,也就无法读取页面中的 noindex 指令,这可能导致页面依然被收录但没有内容摘要。许多网站的收录问题,并不是因为“没拦住”,而是因为“拦得太早”,让搜索引擎无法正确识别页面属性。
在网站上线或改版前,建议系统性地进行 robots.txt 配置检查。以国内外大型网站为例,超过80%的抓取异常都与 robots.txt 配置失误有关,比如文件未放在根目录、编码格式错误、规则误伤了 CSS、JS 或图片资源,或者 Sitemap 地址不可访问等。每一次 robots.txt 的修改,都应结合日志分析和缓存刷新,确保新规则及时生效,避免因缓存延迟导致的抓取混乱。
很多抓取管理的问题,并不是技术难度高,而是目标和规则没有区分清楚。只要明确一点:你是想减少无价值抓取,还是想彻底隐藏内容?前者适合用 robots.txt,后者则必须依赖更严格的权限和安全措施。把这个边界守住,才能让网站抓取管理更稳健,SEO 优化也会更有方向感。
参考资料
- Google Search Central: robots.txt 规范
- Bing Webmaster Guidelines: Robots.txt
- 百度搜索资源平台:Robots 协议详解
- Robots Exclusion Protocol (REP) 官方标准
- Google Search Central: 控制抓取和索引
- Google 官方博客:Robots.txt 的常见误区
- Ahrefs Blog: How to Use Robots.txt for SEO
- Moz: The Robots.txt File and SEO
- 百度站长平台:robots.txt 工具
- Google Search Central: 如何测试 robots.txt 文件